Cloudflare Pagesで `Failed: build output directory contains links to files that can't be accessed` が出た時の対応
Nuxt3で作成したプロジェクトをCloudflare Pagesにデプロイするときに、表題のエラーが出ました。
Failed: build output directory not found 等は結構ググれば出てくるし、何となく意味もわかるのですが、こちらは見つからず。
解決方法は単純で、 ビルド出力ディレクトリ の部分を、 /dist から /.output/public に変更すればOKでした。
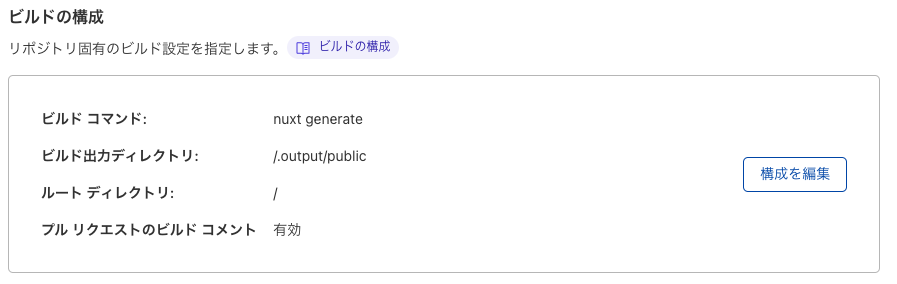
generateを実行した際、 /dist が元々 /.output/public へのリンクになっていたと思うんですが、それがうまく貼られなかったということなんですかね...。
React + vitestでrenderするDOMの内容を確認したい時
前記事でvitestを色々試していた時に、renderしたdomの内容を確認したい状況が何回もありました。
前記事の内容をサンプルにすると、以下のように書けます。
// @vitest-environment happy-dom import React from 'react'; import '@testing-library/jest-dom'; import { render } from '@testing-library/react'; import { describe, expect, test, vi } from 'vitest'; import Title from '@/Components/Layout/Title'; describe('Screen Display', () => { test('Display `title - MyPage` title', async () => { const { debug } = render(<Title title="test" />, { container: document.head }); debug(); // ここで表示 expect(document.head.querySelector('title')?.innerHTML).toEqual( 'test - MyPage' ); }); });
これを実行すると、ターミナル上でDOMの内容が表示されます。
❯❯ npm run test
> test
> vitest run
~~~
<head>
<title>
test - MyPage
</title>
</head>
~~~
というわけで、 render() の返り値として、 debug() を受け取り、それを実行するれば良かったという話でした。
Laravel+Inertia.js+Vitestで `TypeError: Cannot read properties of undefined (reading 'createProvider')` が出た時の対応
Inertia.jsという存在を最近知り、面白いと思ったので、フロントエンドは苦手ではありますが、色々試していました。
Inertia.js - The Modern Monolith
そういった状況で表題のエラーが出たので、調べた備忘録です。
一旦やりたかったことは出来ましたが、正攻法かは分かりません。
2022/11/05:別の対応法を確認出来たので追記
環境
- Laravel: 9.19
- @inertiajs/inertia: 0.11.1
- @inertiajs/inertia-vue3: 0.6.0
- vue: 3.2.4
- vite: 3.0.0
- vitest: 0.24.3
エラー内容
下記のようなファイルを resources/js/Pages 以下に作成します。
// Welcome.vue
<script setup>
import { onMounted } from "vue";
import { Head } from "@inertiajs/inertia-vue3";
onMounted(() => {
console.log("Welcome Page mounted");
});
</script>
<template>
<Head>
<title>Welcome</title>
</Head>
<h1>Welcome Inertia.js</h1>
</template>
// Welcome.test.js
// @vitest-environment happy-dom
import { mount } from '@vue/test-utils'
import { describe, expect, test } from 'vitest'
import Welcome from './Welcome.vue'
describe('Screen Display', () => {
test('Display `Welcome` message', () => {
const wrapper = mount(Welcome)
expect(wrapper.text()).toContain('Welcome')
})
})
この状態で、vitestを実行すると以下のエラーになります。
❯❯ npm run test
> test
> vitest run
RUN v0.24.3 /laravel_inertia
❯ resources/js/Pages/Welcome.test.js (1)
❯ Screen Display (1)
× Display `Welcome` message
❯ Proxy.data node_modules/@inertiajs/inertia-vue3/dist/index.js:1:5942
❯ applyOptions node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:3384:34
❯ finishComponentSetup node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:7257:9
❯ setupStatefulComponent node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:7168:9
❯ setupComponent node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:7090:11
❯ mountComponent node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5448:13
❯ processComponent node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5423:17
❯ patch node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5027:21
⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯ Failed Tests 1 ⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯
FAIL resources/js/Pages/Welcome.test.js > Screen Display > Display `Welcome` message
TypeError: Cannot read properties of undefined (reading 'createProvider')
❯ mountChildren node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5210:13
❯ processFragment node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5382:13
❯ patch node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5020:17
❯ ReactiveEffect.componentUpdateFn [as fn] node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5562:21
❯ ReactiveEffect.run node_modules/@vue/reactivity/dist/reactivity.cjs.js:191:25
❯ instance.update node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5669:56
❯ setupRenderEffect node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5683:9
❯ mountComponent node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5465:9
❯ processComponent node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5423:17
❯ patch node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5027:21
❯ ReactiveEffect.componentUpdateFn [as fn] node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5562:21
❯ ReactiveEffect.run node_modules/@vue/reactivity/dist/reactivity.cjs.js:191:25
❯ instance.update node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5669:56
❯ setupRenderEffect node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5683:9
❯ mountComponent node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5465:9
❯ processComponent node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5423:17
❯ patch node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:5027:21
❯ render node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:6183:13
❯ mount node_modules/@vue/runtime-core/dist/runtime-core.cjs.js:4417:25
❯ app.mount node_modules/@vue/runtime-dom/dist/runtime-dom.cjs.js:1523:23
❯ Proxy.mount node_modules/@vue/test-utils/dist/vue-test-utils.cjs.js:8002:18
❯ resources/js/Pages/Welcome.test.js:8:20
Test Files 1 failed (1)
Tests 1 failed (1)
⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯[1/1]⎯
Start at 01:05:07
Duration 1.74s (transform 592ms, setup 0ms, collect 145ms, tests 13ms)
調査
記事確認
TypeError: Cannot read properties of undefined (reading 'createProvider') というエラーになっているので、とりあえずこちらのエラー文をググってみると、laracastsのページが出ます。
ただ、残念ながら解決はしていない。
また、inertia-laravelのGitHub issueにも同様の質問が投げられていますが、こちらもまだ回答なし。
ソースコード確認
inertiajs/inertia のソースコードで createProvider を検索してみると、vueやreactのライブラリの各パッケージ用と大元の処理の部分に記載があるようでした。
inertia/head.ts at 66fabda56d2f5e2f645073f619c25cb69b760e91 · inertiajs/inertia · GitHub
この辺りの処理を眺めるとなんとなく、 <title> のタグとかを探したりしていそうです。
vitest動作確認
テストの処理をデバッグしてみます。
console.log を追記してコンポーネントのHTML内容を確認。
// @vitest-environment happy-dom
import { mount } from '@vue/test-utils'
import { describe, expect, test } from 'vitest'
import Welcome from './Welcome.vue'
describe('Screen Display', () => {
test('Display `Welcome` message', () => {
const wrapper = mount(Welcome)
console.log(wrapper.html())
expect(wrapper.text()).toContain('Welcome')
})
})
stdout | resources/js/Pages/Welcome.test.js > Screen Display > Display `Welcome` message Welcome Page mounted <h1>Welcome Inertia.js</h1>
bodyの中身だけ表示されますね。
Welcomeコンポーネントだけ確認しているので、当たり前ではありますが、headの内容が入っていないのはなんか怪しいような気が...?
検証
以下のようにVitestでテストを行いたいファイルと、 Head を読み込むファイルを分割しました。
// Welcome.vue
<script setup>
import { onMounted } from "vue";
onMounted(() => {
console.log("Welcome Page mounted");
});
</script>
<script>
import Layout from "./Layout.vue";
export default {
layout: Layout,
}
</script>
<template>
<h1>Welcome Inertia.js</h1>
</template>
// Lauout.vue
<script>
import { Head } from "@inertiajs/inertia-vue3";
export default {
components: {
Head,
}
}
</script>
<template>
<Head>
<title>Welcome</title>
</Head>
<main>
<slot />
</main>
</template>
結果、vitestが通りました。
❯❯ npm run test
> test
> vitest run
RUN v0.24.3 /laravel_inertia
stdout | resources/js/Pages/Welcome.test.js > Screen Display > Display `Welcome` message
Welcome Page mounted
✓ resources/js/Pages/Welcome.test.js (1)
Test Files 1 passed (1)
Tests 1 passed (1)
Start at 01:17:37
Duration 1.66s (transform 618ms, setup 0ms, collect 197ms, tests 13ms)
推測
vitestでテストしたいファイルと、 Head でhead要素を書き換える処理を行なっている部分を別ファイルに分割することで、対応は出来ました。
ということで、 Head が処理する内容がvitestで描画して確認する範囲に存在しないため、出ているエラーだったんじゃないかと推測しました。
ただ、これがあっているのかはちょっと分かりません...。
GitHubのissueにはとりあえずこの記事の対応でコメントしておいたので、もし間違っていた場合は詳しい方が指摘していただけることを願います。
やっぱりフロントエンドは苦手ですが、今回は調べていてちょっと楽しかったです。
2022/11/05追記
分離してテストから外すという方法がなんとなく気持ち悪かったので、諦めずに他の方法を探していました。
すると、Next.jsの方で同じような記事を発見。こちらはjestでの記述ですが、ほぼ同じ記述で再現することが出来ました。
next/headを使ったmetadataを React Testing Library でテストする
How to test metadata using jest and react library test · Discussion #11060 · vercel/next.js · GitHub
Reactで書いていますが、要するにHead部分をmock化すれば良いので、Vueでも似たような方法で書けると思います。
// Title.tsx import React from 'react'; import { Head } from '@inertiajs/inertia-react'; type TitlePrpps = { title: string; }; function Title(props: TitlePrpps) { const { title } = props; return ( <Head> <title>{title ? `${title} - MyPage` : 'MyPage'}</title> </Head> ); } export default Title;
// Title.test.tsx // @vitest-environment happy-dom import React from 'react'; import '@testing-library/jest-dom'; import { render } from '@testing-library/react'; import { describe, expect, test, vi } from 'vitest'; import Title from '@/Components/Layout/Title'; vi.mock('@inertiajs/inertia-react', () => ({ Head: ({ children }: { children: Array<React.ReactElement> }) => ( <>{children}</> ) })); describe('Screen Display', () => { test('Display `title - MyPage` title', async () => { render(<Title title="test" />, { container: document.head }); expect(document.head.querySelector('title')?.innerHTML).toEqual( 'test - MyPage' ); }); });
An error occurred (ServiceNotFoundException) when calling the UpdateService operationが出た時の対応
以下のようなコマンドを打った際に表題のエラーが出ました。
$ aws ecs update-service --cluster {Cluster名} --service {Service名} --task-definition {Task定義名}
下記内容を確認する必要がありました。
- Service名が正しいかどうか
- Cluster名が正しいかどうか
エラー内容の ServiceNotFoundException に気を取られて、Service名にのみ気を取られてしまいましたが、Serviceが動いているCluster名の間違いにも気をつけないといけなかったですね...。
こんなことで1時間ほど溶かしてしまった...。
AWSのアカウントIDやユーザーを忘れた時の対応(CLI)
私用のAWSにログインするのが久しぶりすぎてアカウントIDを忘れてしまい、コンソールにログイン出来なかったことはありませんでしょうか。私はありました。
ちょっとだけ焦ったのですが、下記AWS CLIのコマンドを実行するだけで解決しました。
$ aws sts get-caller-identity { "UserId": "AAAAAAAAAAAAAAAAAAAAA", "Account": "012345678912", "Arn": "arn:aws:iam::012345678912:user/hoge" }
私の場合は、CLIの設定だけしていて、コンソールへのログイン方法を忘れた状態だったので上記解決方法が使用可能でしたが、それが出来ない状態もあり得ますので、アカウント情報は安全な方法で保管しておかないといけないですね。
CodeDeployで遭遇したエラー
CodeDeployを初めて触ってみたのですが、すごい単純なミスをしてしまったので備忘録です。
ググってもCodeDeploy AgentのGitHubソースコードしか出てこなかったので、もし同じようなミスをするような人が現れた時のために書いておきます。
遭遇したエラー
appspec.ymlの記述ミス
実行に失敗した時のappspec.ymlとエラー内容が以下です。
version: 0.0 os: linux files: - source: / destination: /home/ec2-user hooks: ApplicationStart: - location: scripts/start.sh - runas: root
2021-12-01 08:26:07 ERROR [codedeploy-agent(3807)]: InstanceAgent::Plugins::CodeDeployPlugin::Comm andPoller: Error during perform: InstanceAgent::Plugins::CodeDeployPlugin::ApplicationSpecificatio n::AppSpecValidationException - The deployment failed because the application specification file s pecifies a script with no location value. Specify the location in the hooks section of the AppSpec file, and then try again. - /opt/codedeploy-agent/lib/instance_agent/plugins/codedeploy/applicati on_specification/application_specification.rb:90:in `block (2 levels) in parse_hooks'
location の値がないと言われています。ちゃんと書いているのになんでかなと思っていたのですが、正しい書き方は以下です。
version: 0.0 os: linux files: - source: / destination: /home/ec2-user hooks: ApplicationStart: - location: scripts/start.sh runas: root
yamlの書き方を間違ってますね...
配列とハッシュを間違えるのはたまにやってしまうので気をつけたい所存です。
buildspec.ymlの記述ミス(CodeBuildのartifactsにないファイルを実行しようとしている)
エラー文が以下です。
2021-12-01 08:50:51 ERROR [codedeploy-agent(3807)]: InstanceAgent::Plugins::CodeDeployPlugin::Comm andPoller: Error during perform: InstanceAgent::Plugins::CodeDeployPlugin::ScriptError - Script do es not exist at specified location: /opt/codedeploy-agent/deployment-root/b62cd4a6-19fc-4524-bbc3- 88e8d2697ad9/d-4VL3MO17E/deployment-archive/scripts/start.sh
CodePipelineでCodeBuild→CodeDeployとしていたのですが、CodeBuildのbuildspec.ymlで 上記appspec.yml中に指定している scripts/ 以下をartifactsに指定し損ねていました。
まとめ
公式ドキュメントの例をちゃんと見て、小さいミスに気を付けないといけないという教訓でした。
「将棋AIで学ぶディープラーニング」を読んでみての環境メモ
社会人になってからアプリで将棋をちょこちょこ遊んでいますが、最近将棋AIにも興味が出てきたので、こちらの本を買いました。
サンプルコード付きで載っているので、実装はサクサク進められましたし、将棋AIにおける考え方や手法が解説されていて非常に面白かったです。
2018年出版の本のため、色々新しいバージョンで載っているコードを再現してみようと一通り試してみて、環境設定に多少苦労したので備忘録を残しておきます。
本に載っているバージョン通りに環境を設定すればこういった苦労は発生しないものだと思います。
自分の実行環境
PC
- OS: Windows 10 Home(19042.1052)
- CPU: AMD Ryzen 5 3600 6-Core Processor 3.60 GHz
- GPU: NVIDIA GeForce GTX1660
- メモリ: 16GB
主要なパッケージ類
> nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2020 NVIDIA Corporation Built on Thu_Jun_11_22:26:48_Pacific_Daylight_Time_2020 Cuda compilation tools, release 11.0, V11.0.194 Build cuda_11.0_bu.relgpu_drvr445TC445_37.28540450_0 > conda -V conda 4.10.1 > python -V Python 3.7.10
cupy-cuda110==7.8.0 chainer==7.8.0
> python Python 3.7.10 (default, Feb 26 2021, 13:06:18) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import cupy >>> import cupy.cudnn >>> import chainer >>> chainer.print_runtime_info() Platform: Windows-10-10.0.19041-SP0 Chainer: 7.8.0 ChainerX: Not Available NumPy: 1.20.3 CuPy: CuPy Version : 7.8.0 CUDA Root : C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.0 CUDA Build Version : 11000 CUDA Driver Version : 11030 CUDA Runtime Version : 11000 cuBLAS Version : 11100 cuFFT Version : 10200 cuRAND Version : 10201 cuSOLVER Version : (10, 5, 0) cuSPARSE Version : 11100 NVRTC Version : (11, 0) cuDNN Build Version : 8002 cuDNN Version : 8101 NCCL Build Version : None NCCL Runtime Version : None CUB Version : Enabled cuTENSOR Version : None iDeep: Not Available
注意点
CUDAとCuPyのバージョンを合わせる
下記サイトが非常に参考になりました。
int() argument must be a string, a bytes-like object or a number, not 'NoneType'
環境を整えて、 7.9 学習実行 でtrain_policy.py を実行したら上記エラーになりました。
根本的なエラー原因はちゃんと確認していませんが、下記のように値がNoneだった場合に0に置き換えるという対応でひとまずエラーは出なくなりました。
※ 機械学習的にこれが問題ない処理なのかは未検証
def mini_batch(positions, i, batchsize): mini_batch_data = [] mini_batch_move = [] for b in range(batchsize): features, move, win = make_features(positions[i + b]) if features is None: features = 0 if move is None: move = 0 mini_batch_data.append(features) mini_batch_move.append(move)
Anaconda仮想環境で実行されるバッチ作成
Shogi GUIで作成したAIを実行するためにbatでプログラムを呼び出します。
Anaconda仮想環境を使って開発している場合は以下のようなbatにする必要があります。
@echo off
call C:\Users\{ユーザー名}\anaconda3\Scripts\activate.bat
call activate {仮想環境名}
python -m pydlshogi.usi.usi_policy_player 2>NUL
雑感
将棋AIを実際に作成できて楽しかったです。作成したAIが四間飛車を指してきたときは結構感動しました。
次はもっと大量の棋譜を読み込ませての学習と高速化を試してみたい所存です。