EverMonkeyを導入してみた
やったこと
VSCodeでEverNoteとの連携を可能にする拡張機能の一つであるEverMonkeyの導入。最近Markdownでメモを取りたくなり、導入してみたが結構設定までが面倒だったので書いておく。
導入方法
EverMonkeyの導入
設定ページを開く
・GUI操作: Code→基本設定→Settings
・Windows: Ctr + ,
・Mac: ⌘ + ,EverMonkeyの設定で「Note Store Url」「Token」の2つに設定を追記する


上記の3で追記するEverNoteの設定値を取得するのにかなり手間取った。(簡単な方法があったなら教えて欲しいです...)
EverNoteからの情報取得
「Note Store Url」と「Token」を入手するには下記ページからEverNote APIを使う申請をする必要があります。
http://dev.evernote.com/doc/articles/dev_tokens.phpdev.evernote.com右上の「GET AN API KEY」からフォームを開いて必要な情報を入力します。


自分はアプリ名とか説明は適当にtestとかで埋めて、API PermissionsはFull Accessを、チェックは全て付けて申請を出しました。
サポートから申請時に入力したメールアドレスにAPI Keyの情報が送られてきます。割とすぐに来ました。

API Keyを本番環境で有効にする申請をする。
現状でもsandbox(開発)環境でなら先ほど入手したAPI Keyを使って自作のEverNote用ツールのテスト等を行うことは出来ますが、実際の自分のアカウントでは利用出来ません。下記ページから有効にする申請をします。Permissionsはcreate,read,update全部書いておきました。
dev.evernote.com
これはAPI Keyの申請よりも返事が来るのに少し時間がかかりました。それでも2,3日でまたサポートから本番環境で有効にしてくれたメールが届く。必要なTokenを入手します。
サイトの案内に従い下記サイトの「Getting Developer Token」からTokenを入手します。本番環境で使う前にsandbox環境で使うことを推奨されています。 http://dev.evernote.com/doc/articles/dev_tokens.phpdev.evernote.com
私の場合、ここで本番環境のTokenを入手しようとすると「Update: the creation of developer tokens is temporarily disabled.」というエラーになりTokenを作成できませんでした。

こちらのサイトではActivationの申請をしたら使えていた様子ですので何か間違ったんですかね。軽く調べましたが「サポートに問い合わせよう」以上の回答は見つかりませんでした...。
kkobayashi-a.hatenablog.comSDK利用
5で情報を取得出来なかったので、提供されているSDKを動かしてTokenを入手します。このサンプルアプリを動かせれば必要な情報2つが入手できます。 http://dev.evernote.com/doc/dev.evernote.com
私はRubyを利用しました。躓いたのは下記です。- ruby -rubygems evernote_oauth.rb実行時に下記エラーが出たのでgem update --system実行したら通った
`ubygems.rb' is deprecated, and will be removed on or after 2018-12-01. Remove `-rubygems' from your command-line, or use `-r rubygems' instead - アクセス先URLを「https://sandbox.evernote.com」から「https://www.evernote.com」に変更が必要

- ruby -rubygems evernote_oauth.rb実行時に下記エラーが出たのでgem update --system実行したら通った
動作テスト
 * EverNote側で連携されていることを確認
* EverNote側で連携されていることを確認

まとめ
Marxicoを利用しようとしていたけど有料なのに気付き代替の方法として使うが、EverNoteのAPI利用が非常に手間で面倒だった。日本語のドキュメントも少ない。普通にBoostnote使った方が早かったかもしれない。
Django+MongoDBを使ってみた
作ったもの
自然言語処理100本ノックの69問目の問題で無駄に凝ってDjango+MongoDBでWebアプリケーションを作成した。
69.Webアプリケーションの作成
ユーザから入力された検索条件に合致するアーティストの情報を表示するWebアプリケーションを作成せよ.アーティスト名,アーティストの別名,タグ等で検索条件を指定し,アーティスト情報のリストをレーティングの高い順などで整列して表示せよ.
ソースはGitHubに置いています。
Django+MongoDBの記事が意外と少なくて苦労したので書きましたが、正直よくわかっていない所もあるので、間違っている箇所があったら指摘していただきたく。題意を満たす動作しか確認できていません。
※2019/02/18 不要な記述が多かったので大幅修正
使用例
- トップ画面
 * アーティスト名「Queen」で検索
* アーティスト名「Queen」で検索
 * タグ「jpop」で検索&「レーティング(平均)」で降順にソート
* タグ「jpop」で検索&「レーティング(平均)」で降順にソート

内容
各種バージョン
OS : macOS High Sierra(10.13.4)
Anaconda : 4.5.11
Python : 3.6.0
pip : 19.0.2
MongoDB : 4.0.4
Django : 2.1.3
Djongo : 1.2.31
手順
基本的に下記サイトを参考にしています。分かりやすかったです。
細かい内容はこちらを見て頂ければ良いかと思います。
本ブログでは自分が書き換えた箇所のみを書いていこうかと。
パッケージ導入
必要なものは当然ですがDjangoと、DjangoでMongoDBを利用するために必要なDjongoをインストールする。
$ pip install django
$ pip install djongo
公式サイトに書いてあるが、Pythonは3.6以上、MongoDBは3.4以上が必要らしいので注意。 nesdis.github.io
また、DjangoでMongoDBを利用するためのパッケージにはdjango-mongodb-engineというものもあるが設定がうまくいかなかったので断念。
プロジェクト作成
$ django-admin startproject NLP_100knoks_69
$ tree NLP_100knoks_69/
NLP_100knoks_69/
├── NLP_100knoks_69
│ ├── __init__.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
└── manage.py
$ cd NLP_100knoks_69
$ python manage.py startapp webapp
- settings.pyのINSTALLED_APPSに「webapp」を追記
Model作成
とりあえず以下のように作成。
※ここが一番要検討箇所
from djongo import models # Create your models here. class Artist(models.Model): #id = models.IntegerField() gid = models.CharField(max_length=100) name = models.CharField(max_length=30) sort_name = models.CharField(max_length=30) area = models.CharField(max_length=20) aliases = models.ListField(models.EmbeddedModelField('Aliase')) begin = models.EmbeddedModelField('Begin') end = models.EmbeddedModelField('End') tags = models.ListField(models.EmbeddedModelField('Tag')) rating = models.EmbeddedModelField('Rating') objects = models.DjongoManager() class Aliase(models.Model): name = models.CharField(max_length=30) sort_name = models.CharField(max_length=30) class Begin(models.Model): year = models.IntegerField() month = models.IntegerField() date = models.IntegerField() class End(models.Model): year = models.IntegerField() month = models.IntegerField() date = models.IntegerField() class Tag(models.Model): count = models.IntegerField() value = models.CharField(max_length=30) class Rating(models.Model): count = models.IntegerField() value = models.CharField(max_length=100)
- settings.pyにDjongoを使うこととデータベース名を指定
DATABASES = {
'default': {
'ENGINE': 'djongo',
'NAME': 'test_database',
}
}
- データベースにモデルの反映
$ python manage.py makemigrations $ python manage.py migrate
- データをMongoDBに登録
$ python manage.py shell
下記シェルを実行して登録。
import gzip, json from webapp.models import Artist ipath = '/path/to/artist.json.gz' with gzip.open(ipath+"artist.json.gz", "rt", "utf_8") as f: buf = [] for i,line in enumerate(f): obj = json.loads(line) buf.append(obj) if i % 10000 == 0: Artist.objects.mongo_insert_many(buf) buf = [] Artist.objects.mongo_insert_many(buf)
1つずつ登録すると時間がかかりすぎるので、10000件ごとに登録している。
基本的に元データと同じフィールド名を用いたが、idは普通に使おうとすると下記エラーになった。
ERRORS: webapp.Artist: (models.E004) 'id' can only be used as a field name if the field also sets 'primary_key=True'.
軽く調べたが「id」というキーはデフォルトで利用されているから使えないとか。やむなくidはコメントアウト。IDを用いることはあまりないので問題ないと判断。
View作成
- urls.py
from django.contrib import admin from django.urls import path import webapp.views as webapp_view urlpatterns = [ path('admin/', admin.site.urls), path('artist_list/', webapp_view.ArtistListView.as_view()) ]
- views.py
from django.shortcuts import render from django.views.generic import TemplateView from webapp.models import * # Create your views here. class ArtistListView(TemplateView): template_name = "artist_list.html" def search(self,item = '',content = '',limit = 100): if content == '': artists = Artist.objects.mongo_find() else: if item == 'name': artists = Artist.objects.mongo_find({'name':content}) elif item == 'aliase': artists = Artist.objects.mongo_find({'aliases.name':content}) elif item == 'tag': artists = Artist.objects.mongo_find({'tags.value':content}) limit = artists.count() arts = [] # 100件にしている。全体で921337件あるので表示に時間がかかりすぎる為 for artist in artists[:limit]: art = artist # 別名の整形 if 'aliases' in artist: aliase_name = [] for aliase in artist['aliases']: aliase_name.append(aliase['name']) art['aliases'] = ',\n'.join(aliase_name) # 活動開始日の整形 if 'begin' in artist: begin_date = [] if 'year' in artist['begin']: begin_date.append(str(artist['begin']['year'])) if 'month' in artist['begin']: begin_date.append(str(artist['begin']['month'])) if 'date' in artist['begin']: begin_date.append(str(artist['begin']['date'])) art['begin'] = '/'.join(begin_date) # 活動終了日の整形 if 'end' in artist: end_date = [] if 'year' in artist['end']: end_date.append(str(artist['end']['year'])) if 'month' in artist['end']: end_date.append(str(artist['end']['month'])) if 'date' in artist['end']: end_date.append(str(artist['end']['date'])) art['end'] = '/'.join(end_date) # タグの整形 if 'tags' in artist: tag_contents = [] for tag in artist['tags']: tag_contents.append(tag['value']+':'+ str(tag['count'])) art['tags'] = ',\n'.join(tag_contents) # レーティングの整形 if 'rating' in artist: art['rating_num'] = str(artist['rating']['count']) art['rating_ave'] = str(artist['rating']['value']) arts.append(art) d = { 'objects' : arts } return render(self.request, self.template_name, d) def get(self, request, *args, **kwargs): if request.method == 'GET': if 'search' in request.GET: return self.search(request.GET['search_item'], request.GET['search']) else: return self.search()
HTML
参考サイトにほぼ準拠。ただBootStrapでSB Admin 2は最新版ではだいぶ内容が変わっていたので、下記から以前のバージョンを取得して使用した。全部載せると長くなりすぎるので省略。
Release v3.3.7+1 · BlackrockDigital/startbootstrap-sb-admin-2 · GitHub
最終的なディレクトリ構造
一部省略していますが、最終的に以下のような構造になりました。
$ tree . . ├── NLP_100knoks_69 │ ├── __init__.py │ ├── __pycache__ #以下のファイルを省略 │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── db.sqlite3 ├── manage.py ├── static │ ├── bootstrap #以下のファイルを省略 │ │ ├── dist │ │ ├── js │ │ └── vendor │ └── webapp │ └── css │ └── structure.css └── webapp ├── __init__.py ├── __pycache__ #以下のファイルを省略 ├── admin.py ├── apps.py ├── migrations #以下のファイルを省略 ├── models.py ├── templates │ ├── artist_list.html │ └── base.html ├── tests.py └── views.py
完了
参考サイトではこの後ログイン機能等の実装を行わせていますが、今回は不要なのでここで終了。
Djangoを起動し、localhost:8080/artist_listにアクセスすれば使用できる。
まとめ
せっかくだからとDjangoで作ってみたが、結構面白かった。
正直現状Djangoをあまり活用できている気がしないので、ちゃんと勉強したい。
DjangoでTODOリスト作成
作成したもの
Djangoを用いたTODOリスト作成のためのWebアプリ。TODOリストに追加した内容をグラフ上に配置し、軸を設定したグラフ上をドラッグして配置することで、TODOの中でも優先度を自分の中で整理・可視化できるようなもの。

使用例

動機
動機はTwitterで見かけた下記の投稿。
リスト管理が苦手過ぎて、タスクは「やりたい〜やりたくない」と「かんたん〜たいへん」の二軸だけにした。優先度とか得意不得意とか、なんとなく感覚で分けられて楽になった。 pic.twitter.com/01w4JGkNV6
— Somelu (@Somelu01) 2019年1月11日
面白いと思ったし、これなら作れそうとも思ったので、練習もかねて作ってみた。

内容
Django
参考サイトまんま。GitHubで公開されていたのでブランチ切って作った方がよかったのかもしれない。
JavaScript
canvasを用いて、グラフの描画、登録したTODOリストをグラフ上に描画しドラッグ可能にする、軸名の設定等を行なっている。
下記のように、prototypeで描画とクリックされたかどうかの当たり判定を用意している。このように実装しないと、複数のオブジェクトを個別に動かしたり描画するのが面倒だった為。また、グラフ上に描画する際にはTODOリストの内容と一緒に同じ大きさの枠も作成している。
// TODOリストのコンストラクタ設定 var Todo = function(cv, text){ this.cv = cv this.text = text; this.x = cv.width/2; // 初期位置は真ん中で固定 this.y = cv.height/2; this.dragging = false; } // TODOリストのprototype設定 Todo.prototype = { //TODOの描画 draw: function() { ctx = this.cv.getContext('2d'); text = this.text; ctx.font = "30px serif"; metrics = ctx.measureText(text); ctx.strokeRect(this.x, this.y+5, metrics.width, -30); ctx.fillText(text, this.x, this.y); }, // 当たり判定 isTouched: function(cx, cy){ metrics = this.cv.getContext('2d').measureText(this.text); // キャンバスの左上端の座標を取得 var offsetX = this.cv.getBoundingClientRect().left; var offsetY = this.cv.getBoundingClientRect().top; x = cx - offsetX; y = cy - offsetY; return (this.x < x && (this.x + metrics.width) > x && (this.y-24) < y && this.y > y); } }
工夫した点
canvasで複数のオブジェクトを描画し、個別にドラッグ移動可能にした点。
まとめ
Djangoで作ったけれども、あんまりDjangoである必要はなかった気がする。これも突発的に作りたくなったので作った。バグは気が向いたら修正する。
参考サイト
2019年の抱負
あけましておめでとうございます。
社会人になって8ヶ月経過したことだし、今年はアウトプットを増やしていきたいので、去年やったこととか今年の目標とかをまとめて書いておきます。
技術的なこと以外を書くのは初めて。
2018年にやったこと
- 3月 大学院卒業
- 4月 上京して社会人になる
- 8月 高尾山に登る
- 9月 Oracle Bronze SQLを取る
- 10月 勉強会に行き出す
- 11月 NLPの勉強を始める、GitHubをまともに利用し始める、高川山に登る
- 12月 100本ノックが一旦完了、転職を真剣に検討し始める
2018年詳細
卒業&就職
卒業した&就職した。九州から東京に来たが特に不便に思うこともない。
趣味
高尾山と高川山に登った。女子高生が登山するアニメに影響された後輩に影響された結果。行きはよいよい、帰りは怖いってこういうことかなあと実感する。割と楽しいので今後も続けたい。
後藤井聡太7段とかアニメとかに影響されて将棋も始める。各方面から影響されている。圧倒的振り飛車党。現在将棋ウォーズ3級なのでもう少し頑張りたい。
いろんな所で趣味は何かと聞かれるので、それに答えられるような趣味を見つけたのはよかったと思う。
勉強会
今年行ってみた勉強会等
- 【まつもとゆきひろ氏 特別講演】20代エンジニアのためのプログラマー勉強法
- 大規模IPv6ネットワークスキャンを見つける
- CODE BLUE Reject Con
- Sansan×M3 Tech Night ~レガシーシステムに立ち向かえ!~
- EMNLP2018読み会
- PHPカンファレンス2018
九州にいた頃は1回しか勉強会というものに行ったことがなかったけど、こっちは毎週なにかしらの勉強会が開催されていて参加しやすい印象。種類も多いから興味があるのは見つけやすい。でも仕事の都合上、平日に開催されているのは中々参加できていないので辛い。
資格
Oracle Bronze SQLを取得。現状仕事としてはOracleのDBAみたいなこともしているので、Bronzeを取得するためにとりあえずSQLからとった。普通に難しくてびっくりする。DBAとSQLのどっちを先にとってもいいよと言われたから先に難しそうな方をとったけどもあまり業務で使わない。
転職検討
検討中。
2019年目標
2019年詳細
機械学習
前から興味ある興味あると言いつつ特に何もやってこなかった悪いエンジニアだったので、実際に触ってみる。自然言語処理に興味があって、画像処理にもちょっと興味出て来た。とりあえず自然言語処理100本ノックは終了したので、新しい課題を見つけて実装していきたい。
新しい言語
プロコン
これも興味はあったけれどやってこなかったものの一つ。自分のスキルを上げるためにも挑戦したい。Kaggleにもそのうち挑みたい。
Github&ブログ
何か目標がないと何もしない性格なので、アウトプットは習慣づけるようにしたい。アウトプットは大事だって松本さんも言っていた。ブログには上記目標達を実装した内容を定期的に書く予定。
転職
そのうち
まとめ
自分を追い込むためにも今年の目標を書いた。頑張りたい
ニコニコ静画APIを使ってニコニコ静画で流れてしまったコメントを追うChrome拡張機能を作ってみた
作ったもの
ニコニコ静画のコメント欄で下図のような状況がよくある。
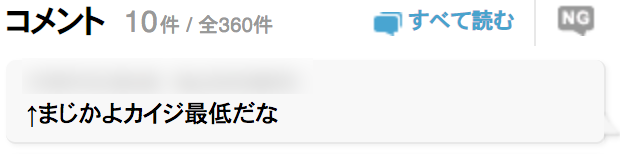
ちょっと分かりにくいかもしれないが、要するにレスを送った対象のコメントが流れてしまって、今表示されているコメントがどんなコメントに対して反応しているのか分からないという状況だ。
図の場合だと、一つ上のコメントに対して反応しているのに、最新の10個しかコメントは表示されていないので対象のコメントは見えなくなっている。これを解消するには「すべて読む」を押して遡る必要がある。
個人的にはそれが結構面倒だったので、下図のように、矢印をマウスオーバーすれば反応している対象を吹き出しに表示してくれるChrome拡張を作ってみた。
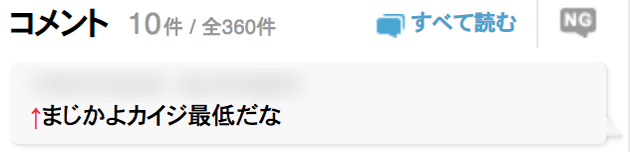
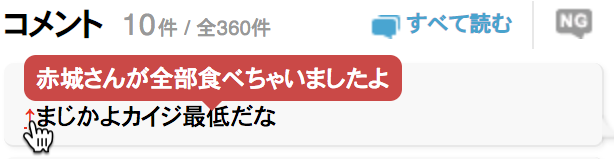
これでわざわざ全てのコメント一覧を開く必要はなくなった。はず。
導入方法
下サイトにソースコードを置いています。
GitHub - ryu022304/niconico_seiga_comment_tracer
そこから下記手順で導入できます。
- 「Clone or download」をクリック
- 「Download Zip」
- ダウンロードしたZipファイルを解凍
- Chromeで「chrome://extensions/」に移動する
- 「パッケージ化されていない拡張機能を読み込む」で先ほど解凍したものを選ぶ
- 以上
技術的内容
http://seiga.nicovideo.jp/ajax/illust/comment/list?id=「静画ID」&mode=allで対象の静画に対するコメントが全て取れる。
本Chrome拡張機能では、アクセスしたページのURLから静画IDを取得して、このAPIを叩いている。
処理の流れとしては以下の通り
1. アクセスしたWebページがニコニコ静画のイラストページだったらURLから静画ID取得
2. content_script.jsからbackground.jsにpostMessageで静画IDを送る
3. 取得した静画IDからニコニコ静画APIを叩いて閲覧している静画の全コメントを取得しcontent_script.jsに結果を返す
4. 矢印等が文頭にあるコメントから反応しているコメントを対応付ける
5. 現在表示されている矢印付きのコメントの矢印部分にマウスオーバーされたときの処理を追加する
6. 以上
まとめ
ニコニコAPIとChrome拡張機能とGitHubを使ってみたかったから作った。
2人日ぐらいで作ったので、バグは折を見て直します。
参考サイト
content_script.jsとbackground.js間の通信
Chrome Extensionのevent pageでAPI通信をおこなう - Qiita吹き出しのデザイン
コピペでできる!CSSとhtmlのみで作るツールチップ | copypet.jp|パーツで探す、web制作に使えるコピペサイト。アイコンの作成
絵文字ジェネレーター - Slack 向け絵文字を無料で簡単生成
The `iconv' command exists in these Python versions
OS : macOS High Sierra(10.13.4)
pyenv : 1.2.4
anaconda : 3-4.3.1
Python : 3.6.0
問題
PCを買い換えて環境をもう一度作り直そうとしてPythonとかMeCabとか入れていたら、mecab-ipadic-NEologdをインストールしようとした段階で下記エラーが出てきた。
(./bin/install-mecab-ipadic-neologd -n)←このコマンド実行時
The `iconv' command exists in these Python versions: anaconda3-4.3.1
macOS Sierra の mecab 辞書に mecab-ipadic-NEologd を入れる
こちらのブログにある方法を試したけれども自分はなんかうまくいかない。
解決方法
という訳で色々また探していたらこのエラーはコマンドの中身は色々違うけれどもPyenv環境で見られるエラーっぽい。
"... command exists in these Python versions" even if there is only one version. #34
そこで、上記サイトの情報を元に下記コマンドを試してみる。
$ pyenv local anaconda3-4.3.1
これで終了。
正直なぜこれで解決できたのかよく分かっていない...
以下テスト
$ echo "このすばって面白い" | mecab この 連体詞,*,*,*,*,*,この,コノ,コノ す 名詞,一般,*,*,*,*,す,ス,ス ばっ 動詞,自立,*,*,五段・ラ行,連用タ接続,ばる,バッ,バッ て 助詞,接続助詞,*,*,*,*,て,テ,テ 面白い 形容詞,自立,*,*,形容詞・アウオ段,基本形,面白い,オモシロイ,オモシロイ EOS
$ echo "このすばって面白い" | mecab -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd/ このすば 名詞,固有名詞,一般,*,*,*,この素晴らしい世界に祝福を!,コノスバ,コノスバ って 助詞,格助詞,連語,*,*,*,って,ッテ,ッテ 面白い 形容詞,自立,*,*,形容詞・アウオ段,基本形,面白い,オモシロイ,オモシロイ EOS
まとめ
Pyenvの使い方ちゃんと勉強しときます。
WebExtensionsのwebNavigation.onCompletedで困ったこと
Firefoxのアドオンを作りたい
今までJVMという環境で作成してきたが、Firefoxのバージョン53以降ではどうやら完全にWebExtensionsで作成したものでなければ動かないらしい。
参考:Getting Started (jpm)
ということでちょこちょこ触ってみて備忘録を書いていこうと思う。
今回やりたいこと
ページを移動するたびにそのページの情報をconsole.logで表示したい。
手法
Event
情報を取得するタイミングはいくつか選べて、主に「navigationが開始された時」(onBeforeNavigate)、「navigationがコミットされた時」(onCommitted)、「DOMが読み込まれ始めた時」(onDOMContentLoaded)、「コンテンツの読み込みが終了した時」(onCompleted)の4つのよう。細かく言うとあと4つ程タイミングはあるようですが、詳しくはこちらを参照。webNavigation
今回は読み込みが全て終了した時をタイミングとする。実装
公式のドキュメント(webNavigation.onCompleted)を参考にしつつ、とりあえず以下のようなコードを作成して、backgroundのscriptとして読み込ませる。表示する情報はURLにしておく。
function logOnCompleted(details) { console.log("onCompleted: " + details.url); } browser.webNavigation.onCompleted.addListener(logOnCompleted);
そして、ブラウザーツールボックス(通常の開発ツールではないことに注意)を開き、適当なWebページに移動すると、下図のようにちゃんとログが出力されているのが確認できる。
追記:通常の開発ツールでも見れました。
"onCompleted: https://www.google.co.jp/"
しかし、ここで色々なサイトにアクセスしているうちに問題が発生した。
下のログがQiitaにアクセスした時の例である。
"onCompleted: https://staticxx.facebook.com/connect/xd_arbiter/r/lY4eZXm_YWu.js?version=42#channel=f39e3d532072bb8&origin=https%3A%2F%2Fqiita.com" "onCompleted: https://platform.twitter.com/widgets/tweet_button.5069e7f3e4e64c1f4fb5d33d0b653ff6.ja.html#dnt=false&id=twitter-widget-0&lang=ja&original_referer=https%3A%2F%2Fqiita.com%2F&size=m&text=Qiita%20-%20%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%9E%E3%81%AE%E6%8A%80%E8%A1%93%E6%83%85%E5%A0%B1%E5%85%B1%E6%9C%89%E3%82%B5%E3%83%BC%E3%83%93%E3%82%B9&time=1512561827145&type=share&url=http%3A%2F%2Fqiita.com&via=Qiita" background02.js:2:3 "onCompleted: https://apis.google.com/se/0/_/+1/fastbutton?usegapi=1&size=medium&origin=https%3A%2F%2Fqiita.com&url=https%3A%2F%2Fqiita.com%2F&gsrc=3p&ic=1&jsh=m%3B%2F_%2Fscs%2Fapps-static%2F_%2Fjs%2Fk%3Doz.gapi.ja.msylnLBdkhc.O%2Fm%3D__features__%2Fam%3DAQ%2Frt%3Dj%2Fd%3D1%2Frs%3DAGLTcCMXw8PTgTYe2ntctyabGs_P9nnIKg#_methods=onPlusOne%2C_ready%2C_close%2C_open%2C_resizeMe%2C_renderstart%2Concircled%2Cdrefresh%2Cerefresh%2Conload&id=I0_1512561827099&_gfid=I0_1512561827099&parent=https%3A%2F%2Fqiita.com&pfname=&rpctoken=22374960" "onCompleted: https://cdn.api.b.hatena.ne.jp/entry/button/?url=http%3A%2F%2Fqiita.com" "onCompleted: https://www.google.com/recaptcha/api2/anchor?k=6LfNkiQTAAAAAM3UGnSquBy2akTITGNMO_QDxMw6&co=aHR0cHM6Ly9xaWl0YS5jb206NDQz&hl=ja&v=r20171129143447&size=normal&cb=h324yenu989z" "onCompleted: https://accounts.google.com/o/oauth2/postmessageRelay?parent=https%3A%2F%2Fqiita.com&jsh=m%3B%2F_%2Fscs%2Fapps-static%2F_%2Fjs%2Fk%3Doz.gapi.ja.msylnLBdkhc.O%2Fm%3D__features__%2Fam%3DAQ%2Frt%3Dj%2Fd%3D1%2Frs%3DAGLTcCMXw8PTgTYe2ntctyabGs_P9nnIKg#rpctoken=380524202&forcesecure=1" background02.js:2:3 "onCompleted: https://www.google.com/recaptcha/api2/bframe?hl=ja&v=r20171129143447&k=6LfNkiQTAAAAAM3UGnSquBy2akTITGNMO_QDxMw6#k16ef81ev35u" "onCompleted: https://qiita.com/" "onCompleted: https://www.facebook.com/plugins/like.php?app_id=222621691108322&channel=https%3A%2F%2Fstaticxx.facebook.com%2Fconnect%2Fxd_arbiter%2Fr%2FlY4eZXm_YWu.js%3Fversion%3D42%23cb%3Df148e8534a9f534%26domain%3Dqiita.com%26origin%3Dhttps%253A%252F%252Fqiita.com%252Ff39e3d532072bb8%26relation%3Dparent.parent&container_width=397&href=https%3A%2F%2Ffacebook.com%2Flike.qiita&locale=en_US&sdk=joey&send=false&show_faces=true&width=380"
なんかいっぱい出て来た。
これはどうやら、https://qiita.com/にアクセスした際に、そのページにiframe要素として、Twitterやfacebookのリンクが埋め込まれており、それを読み込んだ際にもonCompleteが反応していると考えられる。それによって、一つのWebページにしかアクセスしていないのに、複数回イベントが呼び出されてしまうということになっている。
どうにか解決できないかと色々探していたが、公式がwebNavigation.onCompletedのexample extensionとして公開しているコードに答えはあった。
webextensions-examples/navigation-stats/background.js
これを見てみると、コメントにこういうものがある。
「Filter out any sub-frame related navigation event」
見つけた時はだいぶテンションが上がったものである。
これを参考にしてコードを書き換えてみる。ついでに少しすっきりさせる。
browser.webNavigation.onCompleted.addListener(evt =>{ if(evt.frameId !== 0){ return; } console.log("onCompleted: " + evt.url); });
これを再読み込みし、再度Qiitaにアクセスしてみた結果が以下である。
"onCompleted: https://qiita.com/"
成功!
要するに、アクセスしたページ本体のframeIdは0なので、それ以外を弾けば、複数回イベントが発生するという事態は回避できるということだった。
まとめ
公式のexampleはやっぱり役に立つのでちゃんと見よう。